
机器之心报道。
大模型的纯文本方向,已经卷到头了?
刚刚,OpenAI 最大的竞争对手 Anthropic 发布了新一代 AI 大模型系列 ——Claude 3。
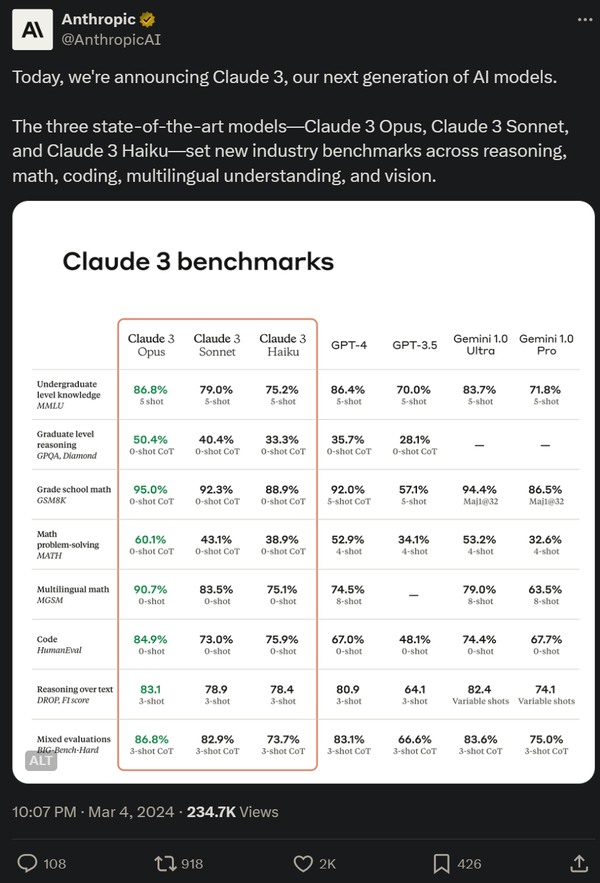
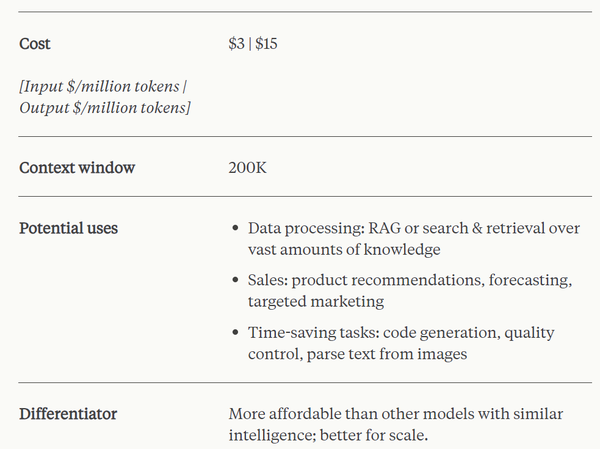
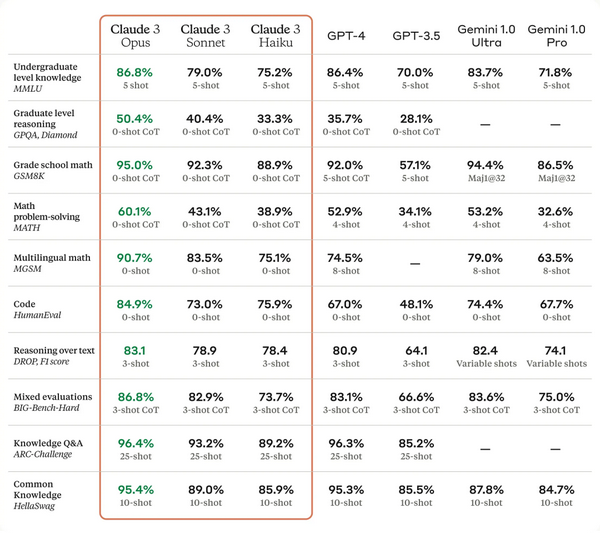
该系列包含三个模型,按能力由弱到强排列分别是 Claude 3 Haiku、Claude 3 Sonnet 和 Claude 3 Opus。其中,能力最强的 Opus 在多项基准测试中得分都超过了 GPT-4 和 Gemini 1.0 Ultra,在数学、编程、多语言理解、视觉等多个维度树立了新的行业基准。
Anthropic 表示,Claude 3 Opus 拥有人类本科生水平的知识。


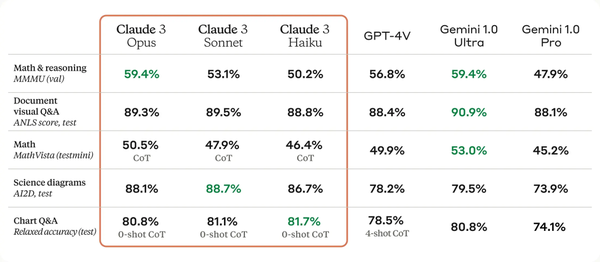
在新模型发布后,Claude 首次带来了对多模态能力的支持(Opus 版本的 MMMU 得分为 59.4%,超过 GPT-4V,与 Gemini 1.0 Ultra 持平)。用户现在可以上传照片、图表、文档和其他类型的非结构化数据,让 AI 进行分析和解答。
此外,这三个模型也延续了 Claude 系列模型的传统强项 —— 长上下文窗口。其初始阶段支持 200K token 上下文窗口,不过,Anthropic 表示,三者都支持 100 万 token 的上下文输入(向特定客户开放),这大约是英文版《白鲸》或《哈利・波特与死亡圣器》的长度。
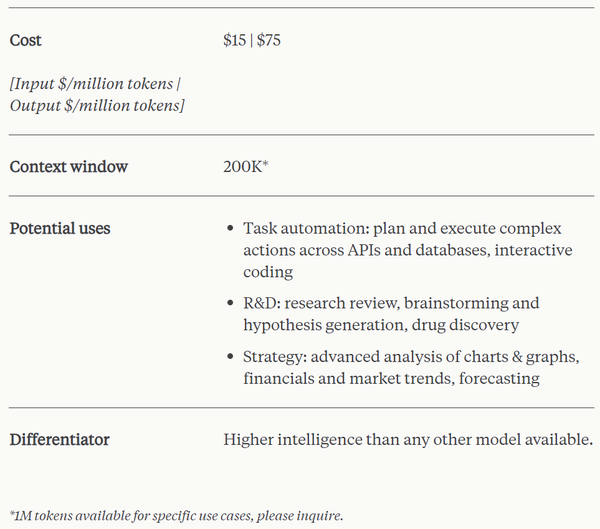
不过,在定价上,能力最强的 Claude 3 也比 GPT-4 Turbo 要贵得多:GPT-4 Turbo 每百万 token 输入 / 输出收费为 10/30 美元 ;而 Claude 3 Opus 为 15/75 美元。


Opus 和 Sonnet 现可在 claude.ai 和 Claude API 中使用,Haiku 也将于不久后推出。亚马逊也第一时间宣布新模型登陆了 Amazon Bedrock。以下是 Anthropic 发布的官方 demo:
demo视频见原文:全面超越GPT-4,Claude 3终于来了,有大学生智商,支持百万token
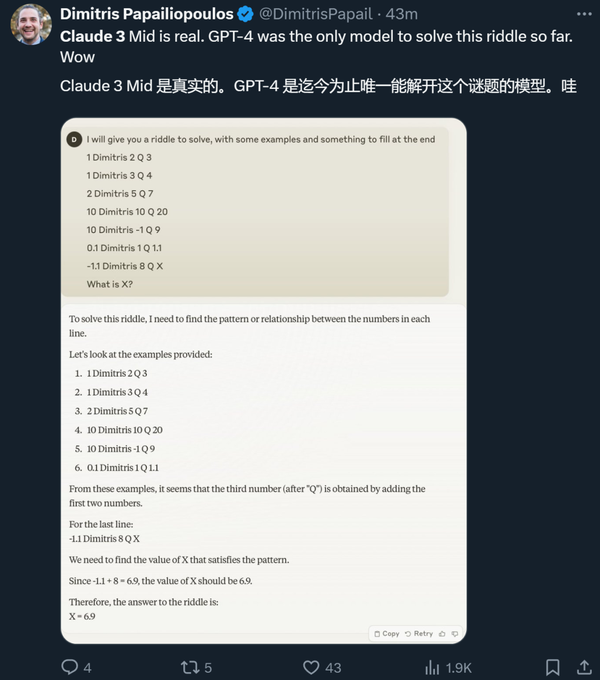
在 Anthropic 官宣之后,不少得到试用机会的研究者也晒出了自己的体验。有人说,Claude 3 Sonnet 解出了一道此前只有 GPT-4 才能解开的谜题。

不过,也有人表示,在实际体验方面,Claude 3 并没有彻底击败 GPT-4。

Claude 3 系列模型
Claude 3 系列模型的三个版本分别是 Claude 3 Opus、Claude 3 Sonnet 和 Claude 3 Haiku。


其中 Claude 3 Opus 是智能程度最高的模型,支持 200k tokens 上下文窗口,在高度复杂的任务上实现了当前 SOTA 的性能。该模型能够以绝佳的流畅度和人类水平的理解能力来处理开放式 prompt 和未见过的场景。Claude 3 Opus 向我们展示了生成式 AI 可能达到的极限。

Claude 3 Sonnet 在智能程度与运行速度之间实现了理想的平衡,尤其是对于企业工作负载而言。与同类模型相比,它以更低的成本提供了强大的性能,并专为大规模 AI 部署中的高耐用性而设计。Claude 3 Sonnet 支持的上下文窗口为 200k tokens。

Claude 3 Haiku 是速度最快、最紧凑的模型,具有近乎实时的响应能力。有趣的是,它支持的上下文窗口同样是 200k。该模型能够以无与伦比的速度回答简单的查询和请求,用户通过它可以构建模仿人类交互的无缝 AI 体验。


接下来我们详看一下 Claude 3 系列模型的特性和性能表现。
全面超越 GPT-4,实现智能水平新 SOTA
作为 Claude 3 系列中智能水平最高的模型,Opus 在 AI 系统的大多数评估基准上都优于竞品,包括本科水平专家知识(MMLU)、研究生水平专家推理(GPQA) 、基础数学(GSM8K)等基准。并且,Opus 在复杂任务上表现出接近人类水平的理解力和流畅度,引领通用智能的前沿。
此外,包括 Opus 在内,所有 Claude 3 系列模型都在分析和预测、细致内容创建、代码生成以及西班牙语、日语和法语等非英语语言对话方面实现了能力增强。
下图为 Claude 3 模型与竞品模型在多个性能基准上的比较,可以看到,最强的 Opus 全面优于 OpenAI 的 GPT-4。

近乎实时响应
Claude 3 模型可以支持实时客户聊天、自动补充和数据提取等响应必须立即且实时的任务。
Haiku 是智能类别市场上速度最快且最具成本效益的型号。它可以在不到三秒的时间内读完一篇包含密集图表和图形信息的 arXiv 平台论文(约 10k tokens)。
对于绝大多数工作,Sonnet 的速度比 Claude 2 和 Claude 2.1 快 2 倍,且智能水平更高。它擅长执行需要快速响应的任务,例如知识检索或销售自动化。Opus 的速度与 Claude 2 和 2.1 相似,但智能水平更高。
强大的视觉能力
Claude 3 具有与其他头部模型相当的复杂视觉功能。它们可以处理各种视觉格式数据,包括照片、图表、图形和技术图表。
Anthropic 表示,它们的一些客户 50% 以上的知识库以各种数据格式进行编程,例如 PDF、流程图或演示幻灯片。因此,新模型强大的视觉能力非常有帮助。

更少拒绝回复
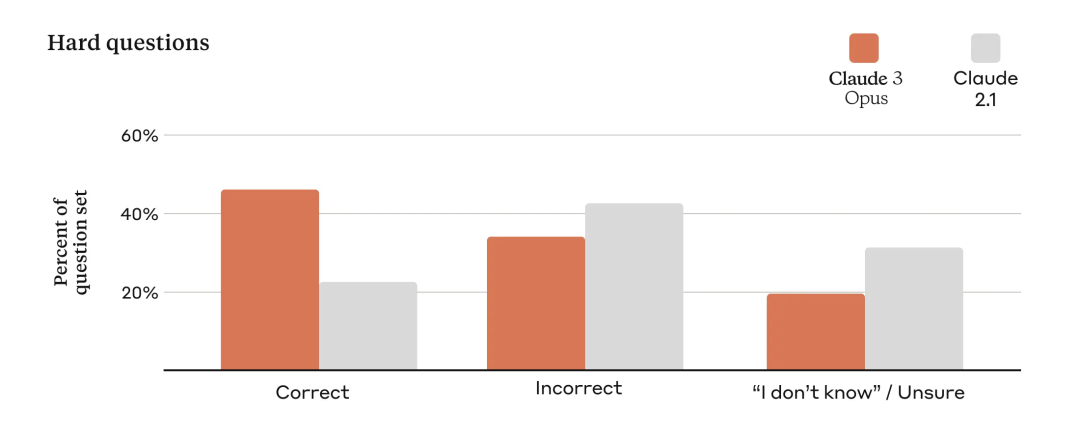
以前的 Claude 模型经常做出不必要的拒绝,这表明模型缺乏语境理解。Anthropic 在这一领域取得了有意义的进展:与前几代模型相比,即使用户 prompt 接近系统底线,Opus、Sonnet 和 Haiku 拒绝回答的可能性明显降低。如下所示,Claude 3 模型对请求表现出更细致的理解,能够识别真正的有害 prompt,并且拒绝回答无害 prompt 的频率要少得多。


准确率提高
为了评估模型的准确率,Anthropic 使用了大量复杂的、事实性问题来解决当前模型中的已知弱点。Anthropic 将答案分为正确答案、错误答案(或幻觉)和不确定性回答,也就是模型不知道答案,而不是提供不正确的信息。与 Claude 2.1 相比,Opus 在这些具有挑战性的开放式问题上的准确性(或正确答案)提高了一倍,同时也减少了错误回答。
除了产生更值得信赖的回复之外,Anthropic 还将在 Claude 3 模型中启用引用,以便模型可以指向参考材料中的精确句子来证实回答。

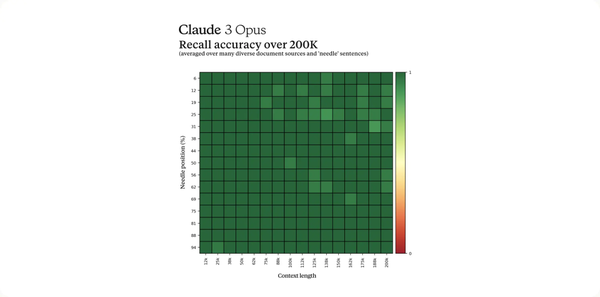
长上下文和近乎完美的召回能力
Claude 3 系列型号在发布时最初将提供 200K 上下文窗口。然而,官方表示所有三种模型都能够接收超过 100 万 token 的输入,此能力会被提供给需要增强处理能力的特定用户。
为了有效地处理长上下文提示,模型需要强大的召回能力。Needle In A Haystack(NIAH)评估衡量模型可以从大量数据中准确回忆信息的能力。Anthropic 通过在每个提示中使用 30 个随机 Needle/question 对在不同的众包文档库上进行测试,增强了该基准的稳健性。Claude 3 Opus 不仅实现了近乎完美的召回率,超过 99% 的准确率。而且在某些情况下,它甚至识别出了评估本身的局限性,意识到「针」句子似乎是人为插入到原始文本中的。

安全易用
Anthropic 表示,其已建立专门团队来跟踪和减少安全风险。该公司也在开发 Constitutional AI 等方法来提高模型的安全性和透明度,并减轻新模式可能引发的隐私问题。
虽然与之前的模型相比,Claude 3 模型系列在生物知识、网络相关知识和自主性的关键指标方面取得了进步,但根据研究,新模型处于 AI 安全级别 2(ASL-2)以内。
在使用体验上,Claude 3 比以往模型更加擅长遵循复杂的多步骤指令,更加可以遵守品牌和响应准则,从而可以更好地开发可信赖的应用。此外,Anthropic 表示 Claude 3 模型现在更擅长以 JSON 等格式生成流行的结构化输出,从而可以更轻松地指导 Claude 进行自然语言分类和情感分析等用例。
技术报告里写了什么
目前,Anthropic 已经放出了 42 页的技术报告《The Claude 3 Model Family: Opus, Sonnet, Haiku》。


报告地址:https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf
我们看到了 Claude 3 系列模型的训练数据、评估标准以及更详细的实验结果。
在训练数据方面,Claude 3 系列模型接受了截至 2023 年 8 月互联网公开可用的专用混合数据的训练,以及来自第三方的非公开数据、数据标签服务商和付费承包商提供的数据、Claude 内部的数据。
Claude 3 系列模型在以下多个指标上接受了广泛的评估,包括:
- 推理能力
- 多语言能力
- 长上下文
- 可靠性 / 事实性
- 多模态能力
首先是推理、编程和问答任务上的评估结果,Claude 3 系列模型在一系列推理、阅读理解、数学、科学和编程的行业标准基准上与竞品模型展开了比较,结果显示不仅超越了自家以往模型,还在大多数情况下实现了新 SOTA。


Anthropic 在法学院入学考试 (LSAT) 、多州律师考试 (MBE)、美国数学竞赛 2023 年数学竞赛和研究生入学考试 (GRE) 普通考试中评估了 Claude 3 系列模型,具体结果如下表 2 所示。


Claude 3 系列模型具备多模态(图像和视频帧输入)能力,并且在解决超越简单文本理解的复杂多模态推理挑战方面取得了重大进展。
一个典型的例子是 Claude 3 模型在 AI2D 科学图表基准上的表现,这是一种视觉问答评估,涉及图表解析并以多项选择格式回答相应的问题。
Claude 3 Sonnet 在 0-shot 设置中达到了 SOTA 水平 —— 89.2%,其次是 Claude 3 Opus(88.3%)和 Claude 3 Haiku(80.6%),具体结果如下表 3 所示。
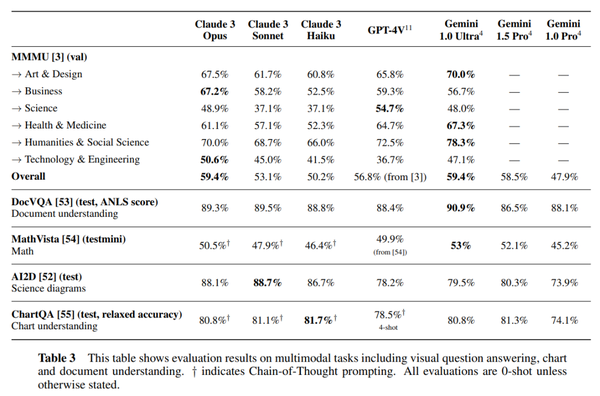

针对这份技术报告,爱丁堡大学博士生符尧在第一时间给出了自己的分析。
首先,在他看来,被评估的几个模型在 MMLU / GSM8K / HumanEval 等几项指标上基本没有区分度,真正需要关心的是为什么最好的模型在 GSM8K 上依然有 5% 的错误。
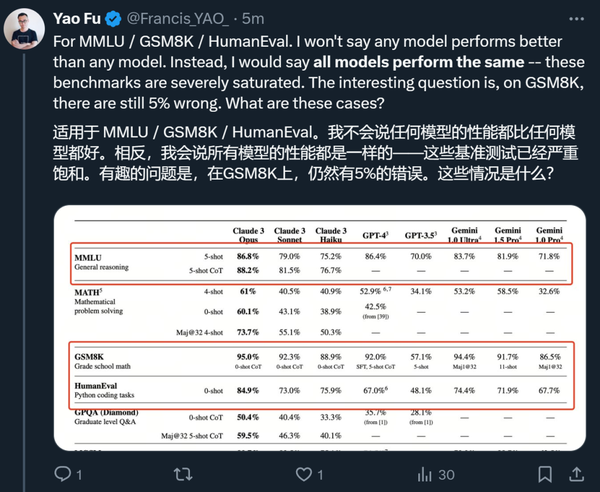

他认为,真正能够把模型区分开的是 MATH 和 GPQA,这些超级棘手的问题是 AI 模型下一步应该瞄准的目标。
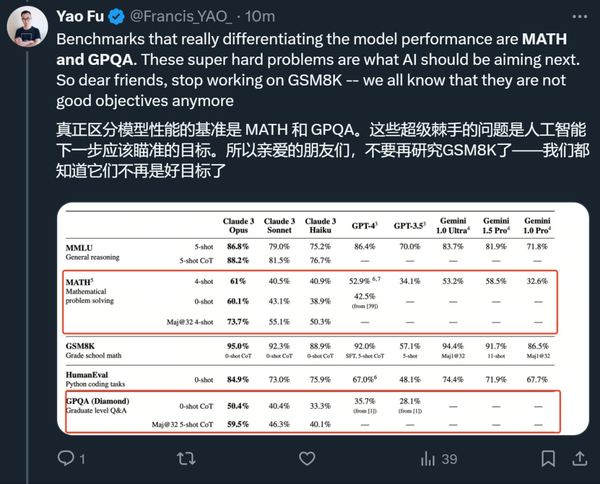

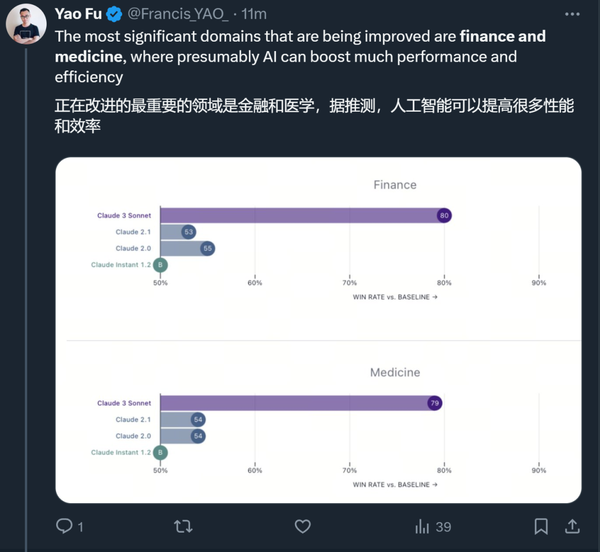
与 Claude 之前的模型相比,改进比较大的领域是金融和医学。

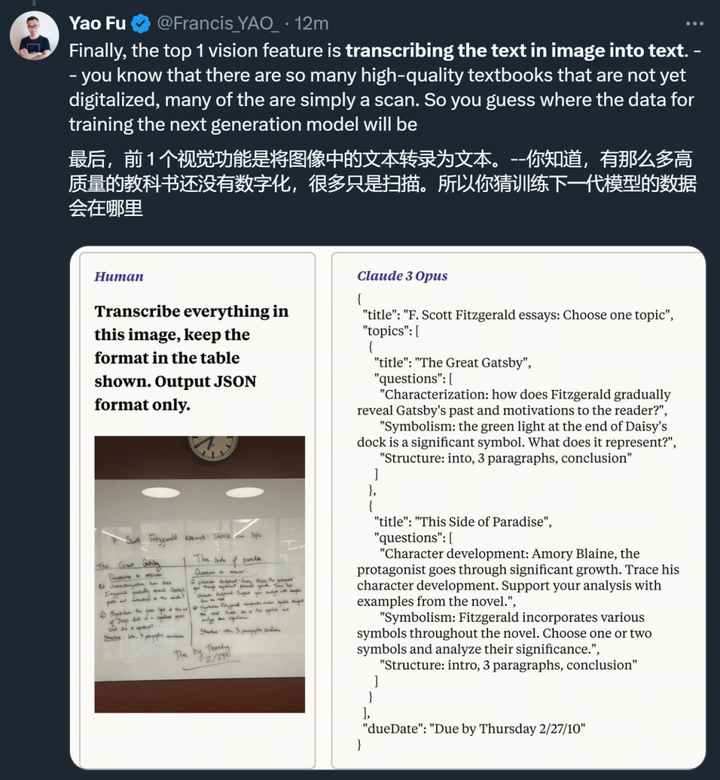
视觉方面,Claude 3 表现出的视觉 OCR 能力让人看到了它在数据收集方面的巨大潜力。

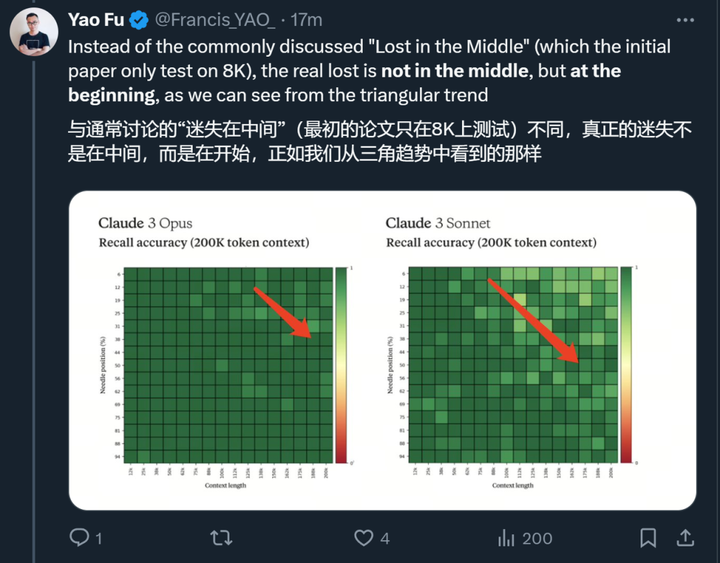
此外,他还发现了其他一些趋势:



从目前的评测基准和体验看来,Claude 3 在智能水平、多模态能力和速度上都取得了长足的进步。随着新系列模型的进一步优化和应用,我们或许将看到更加多元化的大模型生态。
博客地址:https://www.anthropic.com/news/claude-3-family
参考内容:https://www.cnbc.com/2024/03/04/google-backed-anthropic-debuts-claude-3-its-most-powerful-chatbot-yet.html
https://www.aboutamazon.com/news/aws/amazon-bedrock-anthropic-ai-claude-3
文章来源于互联网:全面超越GPT-4,Claude 3终于来了,有大学生智商,支持百万token
相关推荐
-
TikTok Shopping美国小黄车功能及申请条件总览!
10月对于TikTok而言,注定了不平凡。 最近,TikTok不仅官宣其月活达到了10亿,还推出了电商新产品——TikTok Shopping。这是一套集合解决方案、具体功能和广告…
-
TikTok小黄车开通条件,TikTok小黄车开通需要多少钱
TikTok小黄车开通条件 能挂TikTok小黄车的目前有英国区、印尼区和美区,其中前两个是需要开通TikTok Shop也就是小店,然后在视频和直播间都可以挂车。开通印尼小店需要…
-
爆卖1.57万件!联想霸榜TikTok美区小店
作为老牌国货,联想品牌在TikTok Shop美区毫不逊色于其他品牌,旗下一款售价13.59美金的“入耳式无线防水蓝牙耳机”成为“手机数码”类目下的近期热销品,一周共计卖出1.57…
-
TikTok小店本土怎么收款,TikTok小店需要关税或者增值税吗
TikTok小店本土怎么收款 关于收款,目前TikTok小店支持的是派安盈收款,这个没什么复杂的,像虾皮,亚马逊都是支持派安盈收款的,就类似于支付宝,只要注册一下就可以,到时候钱打…
-
Tiktok小黄车【保姆级教程】
01. 东南亚小黄车开通的方式 目前对比英国小店来说,由于东南亚的人口基数要大,所出单还是容易、在售后和退货率方面较少,通过精选联盟或者合作供应链还可以做无货源模式。 在地理位置上…
-
TikTok新手期应该怎样发视频?掌握这些方法快速涨粉百万!
以下全是吐血干货,共计1万2千字和15张图片,大概阅读需要10-35分钟(全文较长,建议点赞+收藏,再慢慢看) 如果你也对海外版某音TK和跨境电商感兴趣,可在下面留言(tk)送大家…
-
拼多多跨境平台Temu入驻申请流程
拼多多跨境平台Temu入驻申请流程 大家好!我是阿迁 拼多多B2C跨境电商平台Temu它来了 9月1日起Temu平台正式上线! 美国是首个站点 其它站点未知。目前全类目开放招商 现…
-
OpenAI Sora 最强文生视频怎么用-新手小白必看教程
1. Sora 是什么AI 2024年2月16日,OpenAI在其官网上面正式宣布推出文本生成视频的大模型 Sora。 Sora能够根据简单的文本描述,生成高达60秒的高质量视频,…